Пакетный перевод 3000 туристических маршрутов на русский через n8n + OpenAI (с поэтапной проверкой качества)
Клиенту нужно было перевести на русский язык большой массив контента для туристических маршрутов: около 3000 строк с названиями и описаниями на разных европейских языках (в основном EN/DE/FR, но без гарантии, что только они).
Обычный чат для такой задачи не подходит: слишком большой объём, нужна пакетная обработка, сохранение структуры файла и предсказуемый результат по всему набору данных. При этом Google Translate клиент сразу исключил, потому что нужен был более аккуратный перевод под туристические описания.
Что было важно для бизнеса
- Перевести весь массив (3000 строк) без ручного копирования по кускам.
- Сохранить структуру Excel-файла, включая скрытые столбцы.
- Сделать промежуточную проверку качества до полного запуска.
- Получить результат в формате, который клиент может сразу импортировать дальше.
- Избежать долгой ручной редактуры после автоматического перевода.
Чтобы снизить риск, работу запускали поэтапно: сначала тестовые записи, затем файл на 500 строк для промежуточной проверки, и только после подтверждения качества — полный прогон.
Если у вас похожая задача (массовый перевод каталога, описаний, карточек, маршрутов, контента для импорта), можно прислать файл и требования в бриф — соберу пакетную обработку и проверочный сценарий под ваш объём.
Что было сделано в n8n
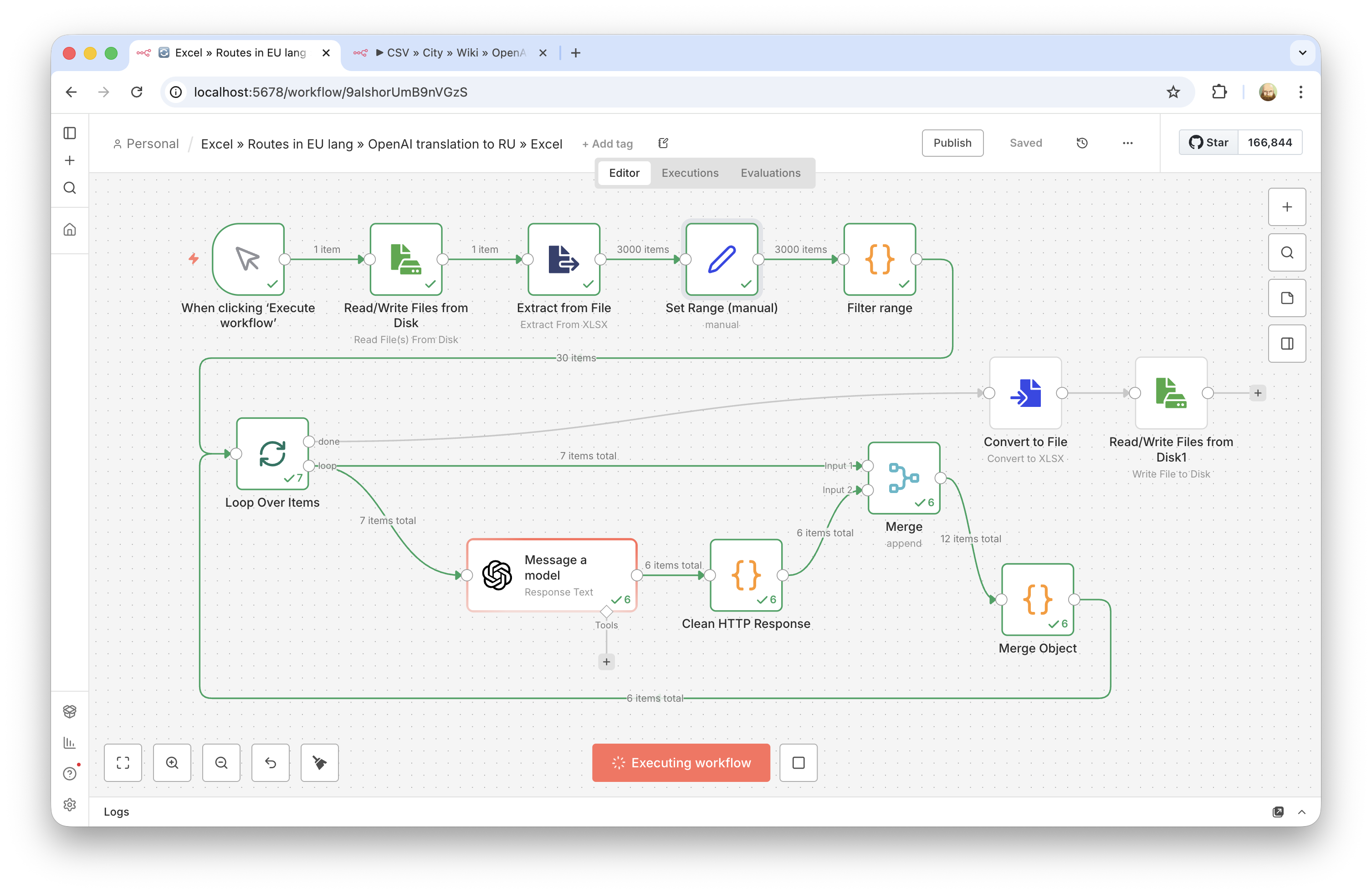
Для задачи был собран workflow в n8n, который обрабатывает строки таблицы пакетно, отправляет в OpenAI перевод названия и описания, получает строго структурированный ответ и записывает результат обратно в выходной файл.
- Подготовлен поток пакетной обработки Excel-данных вместо ручной работы через чат.
- Сделан тестовый прогон на небольшом количестве записей для проверки качества перевода.
- После согласования качества — промежуточный прогон на 500 строк и ручной spot-check.
- После подтверждения клиентом — полный прогон всего массива.
- Сохранён формат передачи результата в Excel (
.xlsx), удобный для дальнейшего импорта у клиента. - Учтено требование по сохранению структуры таблицы (включая скрытые столбцы).
Технические детали: как была устроена обработка
С технической стороны задача была не "просто перевести текст", а сделать устойчивый pipeline для большого файла, чтобы не потерять структуру данных и не получить неуправляемый результат на 3000 строках.
- Пакетная обработка вместо одного большого запроса. Таблица разбивалась на отдельные записи, и каждая строка проходила через один и тот же сценарий перевода. Это устраняет ограничение обычного чата по объёму и позволяет контролировать ошибки построчно.
- Структурированный ответ от модели. Для каждой строки модель возвращала JSON с двумя полями (перевод названия и описания), чтобы результат можно было надёжно маппить обратно в таблицу без ручной чистки.
- Промежуточные проверки качества. Вместо запуска "сразу на всё" делали проверочные этапы: сначала десятки строк, потом 500. Это сильно снижает риск массовой ошибки в промпте или формате.
- Сохранение исходной структуры файла. Важным требованием было не сломать исходный Excel и не потерять скрытые столбцы, поэтому результат отдавался в том же формате (
.xlsx), а не в виде "плоской" выгрузки в CSV/Google Sheets. - Форматирование описаний. По согласованию с клиентом описания оставлялись без HTML-тегов, с переносами строк/абзацами в читаемом виде, чтобы совпадать с существующим форматом данных.
Технические детали: важный вывод по промпту (короче — лучше)
Отдельно интересный момент из этой задачи: сначала был сделан подробный промпт с большим количеством ограничений и уточнений (про тип текста, стиль, формат, списки, формулировки для названий маршрутов и т.д.). Формально он выглядел "правильнее", но на практике оказался переусложнённым.
После обратной связи от клиента промпт упростили. И результат стал лучше: перевод стал ближе к ожиданиям клиента и к его уже проверенному примеру. Это хороший практический пример для автоматизаций на LLM: длинный и детализированный промпт не всегда даёт лучший output, особенно когда заказчику нужен нейтральный массовый перевод, а не сложная стилизация текста.
- Сложный промпт давал больше "самодеятельности" и лишней интерпретации.
- Простой промпт лучше попал в ожидаемый тон и формат.
- Решение принималось не теоретически, а по быстрым тестовым прогонам и просмотру реальных строк.
На практике это означает: в n8n-пайплайнах с LLM стоит закладывать этап короткой A/B-проверки промптов на реальных данных до полного массового запуска.
Результат
- Переведён полный массив около 3000 строк (названия + описания маршрутов).
- Работа выполнена поэтапно с промежуточным согласованием качества (тест -> 500 строк -> полный объём).
- Файл отдан в формате Excel, удобном для дальнейшего импорта у клиента.
- Клиент принял результат и подтвердил качество перевода.
Такой формат хорошо подходит для задач, где нужен не "разовый ответ ИИ", а контролируемый массовый прогон по таблице с проверкой качества и нормальной отдачей результата в рабочем формате.