Supabase (Postgres): витрина сделок по недвижимости для Excel и API
Бывает, что данные по сделкам уже есть - но в виде "простыни" строк, где сложно быстро ответить на базовые вопросы: как меняется цена по месяцам, какие проекты растут, где выбросы, как сравнить 1BR и 2BR.
В этом проекте задача была практичная: навести порядок в данных сделок по недвижимости в Supabase (Postgres) и сделать так, чтобы заказчик мог сам выгружать витрину в Excel и играться автофильтрами без постоянных запросов к разработчику.
Что нужно было получить
- Нормализовать структуру таблиц (проекты, девелоперы, транзакции) и типы данных.
- Связать проекты и девелоперов через ключи
- Сделать аналитику по времени (год/месяц).
- Собрать агрегаты цен по проектам и количеству комнат.
- Ускорить отчётные запросы индексами.
- Отдать наружу готовые выборки через Supabase API (вход: p_id/d_id или "всё").
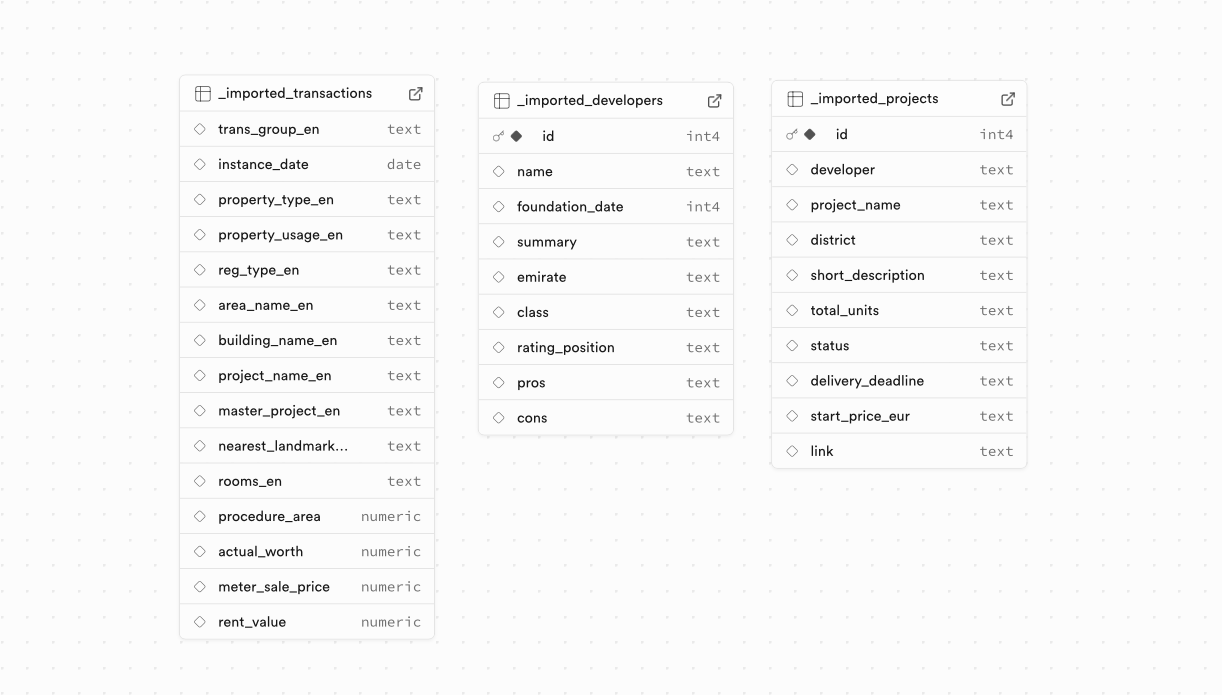
1. Импорт исходных данных
Данные были загружены в Supabase "как есть": без предварительной подготовки схемы, с разнородными типами полей и неустойчивыми значениями (тексты, даты, числа, названия проектов).
От заказчика пришло 2 Excel-файла и 1 CSV-файл объёмом 150 МБы.
Это позволило быстро начать работу с реальными данными и уже на живом объёме видеть проблемы качества и структуры.
2. Кропотливая нормализация и приведение схемы в порядок
Дальше шла аккуратная работа по приведению базы в нормальный вид:
- вынесение справочников (проекты, девелоперы) в отдельные таблицы,
- создание связей между сущностями через ключи,
- приведение типов столбцов (date, numeric вместо text),
- добавление индексов под реальные отчётные запросы,
- обогащение данных (например, нормализация комнатности/спален из текстовых значений в числовые поля),
- добавление отдельных полей p_year и p_month для аналитики по времени.
Поля года и месяца были вынесены отдельно, чтобы не считать EXTRACT(YEAR/MONTH) в каждом запросе и упростить группировки и сортировку при выгрузке в Excel.
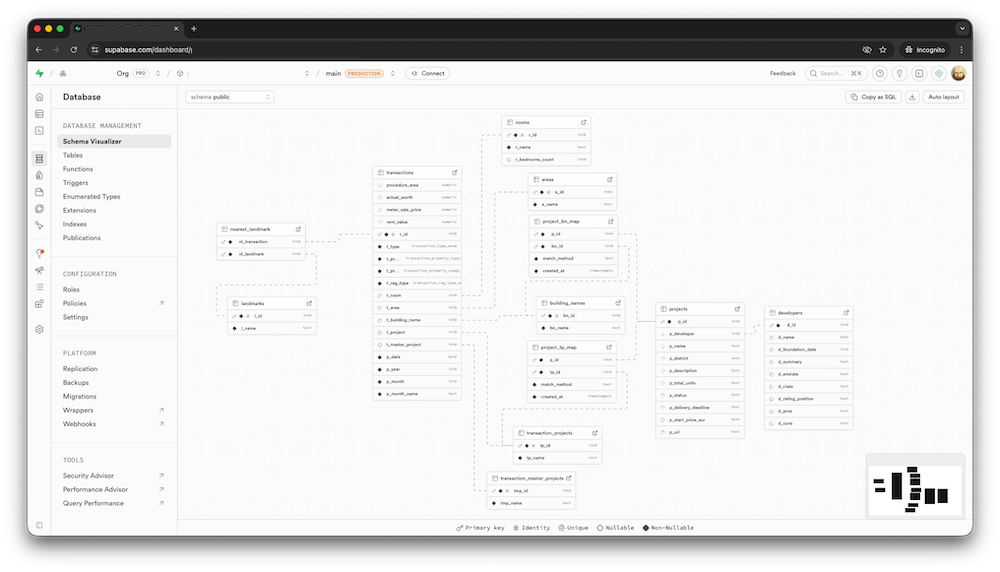
3. Подготовка базы под внешнее API
Структура и запросы были приведены к виду, удобному для внешнего потребления: плоские выборки, стабильные поля, предсказуемые фильтры по ключам (p_id, d_id, год, месяц). Само внешнее API в рамках этой задачи не делали, но база и витрины данных к нему подготовлены.
Результат
- После raw-импорта данные занимали около 300 МБ в Supabase; после нормализации и добавления новых индексов объём снизился до 237 МБ.
- Даже с новыми индексами база полностью укладывалась в лимиты Supabase Free Tier.
- Запросы по аналитике стали выполняться заметно быстрее за счёт индексов и предвычисленных полей по времени.
- База стала пригодна для масштабирования: отчёты, внешнее API, BI-инструменты.
Кому подходит
- Если данные уже есть, но ими сложно пользоваться без ручной чистки.
- Если нужна аналитика по времени (месяц/год) и сравнения по категориям.
- Если результат должен быть "для бизнеса": Excel/BI + API, а не только SQL.
Если нужен похожий результат: привожу таблицы в порядок, проектирую схему под аналитику, собираю витрины и готовлю доступ через API.
Технические детали: как загрузить большой локальный CSV в Supabase
Ниже рабочий сценарий, когда CSV-файл большой и лежит локально на вашем компьютере.
1) Берём IPv4-строку подключения в Supabase
- Откройте проект в Supabase: Project Settings -> Database -> Connection string.
- Выберите режим URI и вариант для IPv4 (Direct connection).
- Скопируйте строку вида:
postgresql://postgres.<project-ref>:<password>@<host>:5432/postgres?sslmode=require2) Запускаем контейнер с Postgres-клиентом и пробрасываем папку с CSV
docker run --rm -it \
-v "$(pwd)":/work \
postgres:16 \
psql "postgresql://postgres.<project-ref>:<password>@<host>:5432/postgres?sslmode=require"Это одна команда: она сразу открывает psql, а текущая папка из терминала монтируется в контейнер как /work.
3) Создаём таблицу в Supabase (через psql)
Перед импортом просто создайте нужную таблицу в Supabase (через SQL Editor или заранее в том же psql).
4) Импортируем CSV в таблицу
Вы уже внутри Docker и подключены к БД в psql, поэтому выполняем команду напрямую:
\copy import.deals_raw
from '/work/deals.csv'
with (format csv, header true, delimiter ',', quote '"', null '');null '' означает: пустые значения в CSV будут загружены как NULL. Если в файле NULL помечен строкой NULL, используйте null 'NULL'.
5) Быстрая проверка
select count(*) as rows_loaded from import.deals_raw;
select * from import.deals_raw limit 5;Если файл очень большой, загружайте его батчами (по частям) и после импорта добавляйте индексы — так обычно быстрее и стабильнее.