Локальный автоматизированный перевод с английского на русский с помощью модели Qwen 2.5 32B
Цель этого теста была прикладной: проверить, можно ли сделать полностью автоматизированный перевод с английского на русский на локальной модели, без зависимости от платных API на основном объёме.
В качестве базы использовался Qwen 2.5 32B. Задача была не просто «получить перевод», а собрать рабочий процесс, который можно запускать на реальных объёмах текста: с предсказуемой скоростью, с контролем качества и с понятной экономикой.
Этот этап напрямую продолжает предыдущий материал по OCR: там был получен исходный LaTeX из PDF, а здесь — его автоматизированный перевод и дополировка качества. Исходный контекст и пример непереведённого блока: пост про DeepSeek OCR 2.
Что было важно для бизнеса
- Переводить большие объёмы EN-контента на RU автоматически, без ручной работы по абзацам.
- Снизить стоимость относительно сценария «всё через платный API».
- Сохранить качество на уровне, пригодном для публикации/дальнейшего использования.
- Сразу предусмотреть контроль «плохих» фрагментов и отдельную обработку только проблемной части.
Ключевая идея: максимально использовать локальный перевод там, где он стабилен, а для небольшой доли сложных фрагментов подключать более дорогой, но точный резервный канал.
Если у вас похожая задача (массовый перевод документации, базы знаний, карточек, контента для сайта) и важно снизить стоимость без потери качества, можно прислать задачу в бриф — соберу гибридный pipeline под ваш объём и требования.
Что получилось в итоге
- Полностью автоматизированный процесс реализован и запущен локально на Mac.
- На CPU сценарий оказался практический непригодным: слишком долго для рабочих объёмов.
- На GPU получилась рабочая скорость и стабильный массовый прогон.
- Около 95% фрагментов перевелись автоматически без вмешательства.
- Около 5% дали артефакты: китайские символы, непереведённые куски, лишние комментарии в output.
Отдельно важный результат: эти 5% можно отлавливать автоматически (правилами и проверками качества) и отправлять в отдельный маршрут на дообработку.
Экономика решения
Если переводить весь массив через платный API, бюджет растёт линейно от объёма текста. В локальном сценарии основная часть затрат уходит в настройку и вычисления на своей машине, а переменная стоимость на каждый следующий запуск заметно ниже.
Практически это дало рабочую модель:
- основной массив переводится локально (дешевле);
- только проблемные 5% отправляются в платный API (дороже, но точечно);
- общая стоимость полного цикла получается существенно ниже, чем «100% через API».
Как обрабатывались проблемные 5%
Плохие фрагменты можно было выявлять автоматически и маркировать для повторного перевода:
- по детектору неожиданных символов/скриптов (например, китайские иероглифы в RU-результате);
- по признакам «непереведённого исходника» (большие EN-куски в целевом RU-тексте);
- по служебным/лишним комментариям, которые не должны попадать в финальный контент.
Для этой небольшой доли можно использовать OpenAI API как второй этап: дороже на единицу текста, но выше качество там, где локальная модель дала нестабильный output. В итоге получается управляемый гибрид: быстро, дешевле в среднем и с качественным финальным результатом.
Технические детали
Ниже — технический контур PoC, который был зафиксирован как рабочий baseline на Mac.
Цель и ограничения PoC
- Перевести LaTeX документ с большим числом заголовков, параграфиов и самое главное сносок на русский с максимально точной юридической передачей смысла.
- Работать локально и без установки инструментов напрямую в macOS.
Итоговая модель (зафиксированный профиль)
Целевой профиль по качеству для этого PoC: Qwen2.5-32B-Instruct в кванте Q4_K_M.
Ссылка на модель: Qwen/Qwen2.5-32B-Instruct-GGUF.
На этом железе рабочая конфигурация в LM Studio: GPU offload max (в UI было 64/64), стартовый контекст 4096.
Отдельно проверяли и более лёгкий квант Q3_K_M: он действительно быстрее, но в юридических фрагментах чаще терял точность формулировок и стабильность терминологии. По итогам PoC зафиксировали Q4_K_M как основной профиль качества.
Как устроен текущий перевод
- Источник режется на блоки по пустым строкам.
- Длинные блоки режутся по предложениям (
. ? !), с безопасным fallback по пробелу/лимиту. - Используется один system prompt (без отдельных review/retry/heading режимов).
\footnote{...}и ссылки (\url,\href,\hyperref,\nolinkurl,\path) не переводятся.
Валидация и авто-контроль качества
- Запрет meta-комментариев модели в ответе (
Note,Correction,Finalи т.п.). - Запрет markdown code-fence в переводе.
- Проверка на английские ключевые морские термины в RU-результате.
- Отдельная детекция CJK-символов, лишних переносов, дублей и прочих артефактов «грязного» ответа.
Что тестировали по моделям
qwen2.5:7b: быстрее, но хуже терминология и устойчивость на сложных абзацах.qwen2.5:14b: лучше 7b, но всё ещё встречались некачественные формулировки и мультиязычный дрейф.qwen2.5:32b: заметно лучше качество, но высокая требовательность к памяти и вычислительным ресурсам; при нехватке ресурсов возникали ошибки выполнения и нестабильные ответы.
Почему CPU не взлетел, а GPU стал baseline
- На CPU длинные чанки давали слишком долгие таймауты/ретраи, что делало полный прогон непрактичным.
- Критичным оказался не только промпт, но и ресурсный профиль окружения (сначала ресурсы, потом тюнинг).
- На Mac GPU с профилем
Q4_K_Mполучили ускорение в несколько раз при приемлемом юридическом качестве.
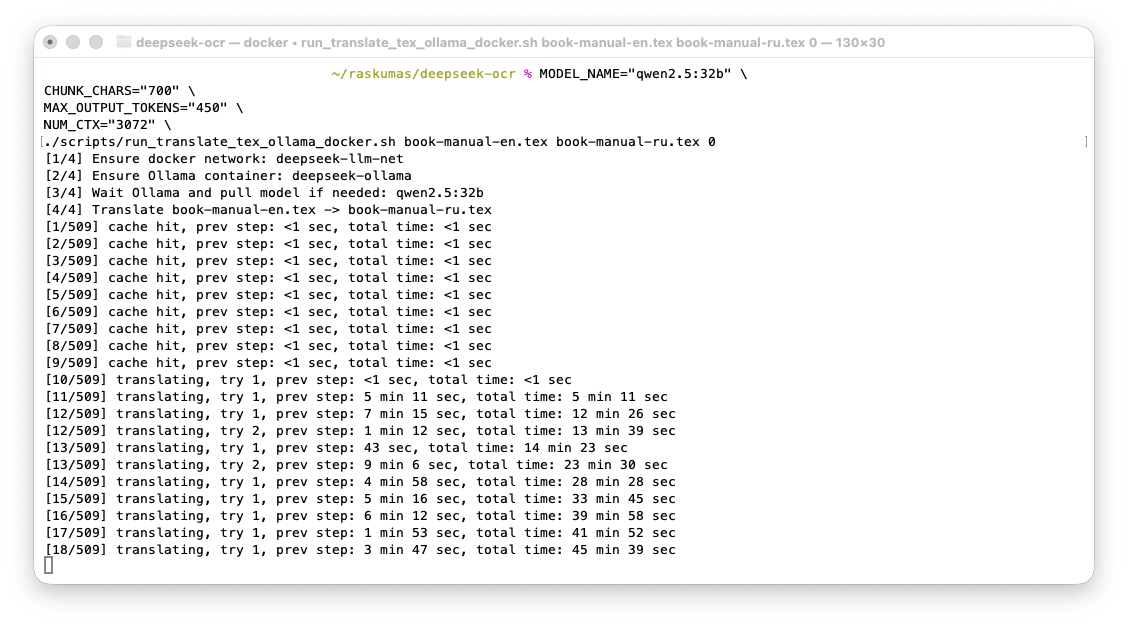
Рисунок 1. CPU-прогон: время перевода одного абзаца в диапазоне примерно 5-9 минут.
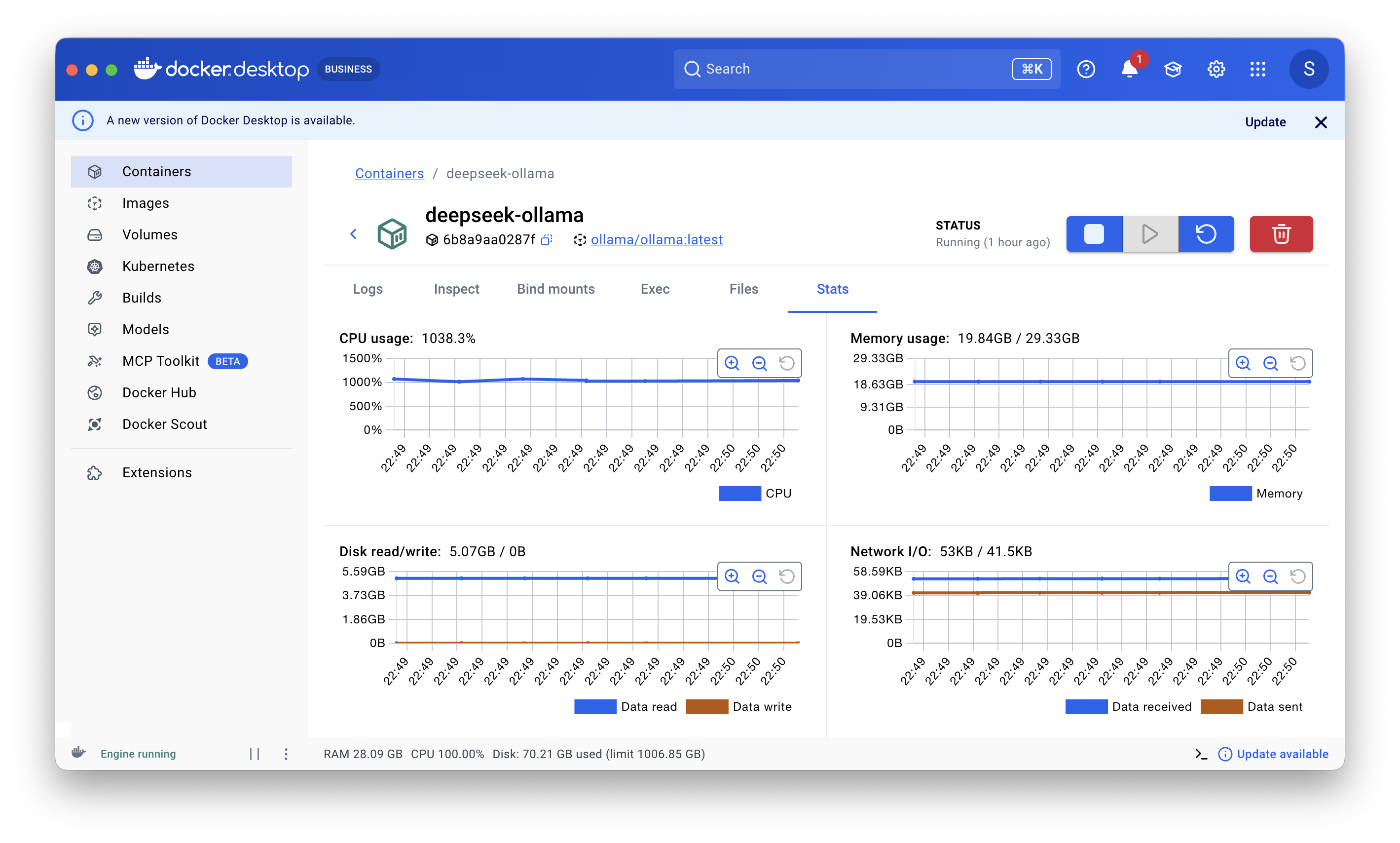
Рисунок 2. Для CPU-запуска использовался Docker; по скриншоту видно потребление памяти порядка 20 ГБ. GPU-запуск выполнялся отдельно в LM Studio.
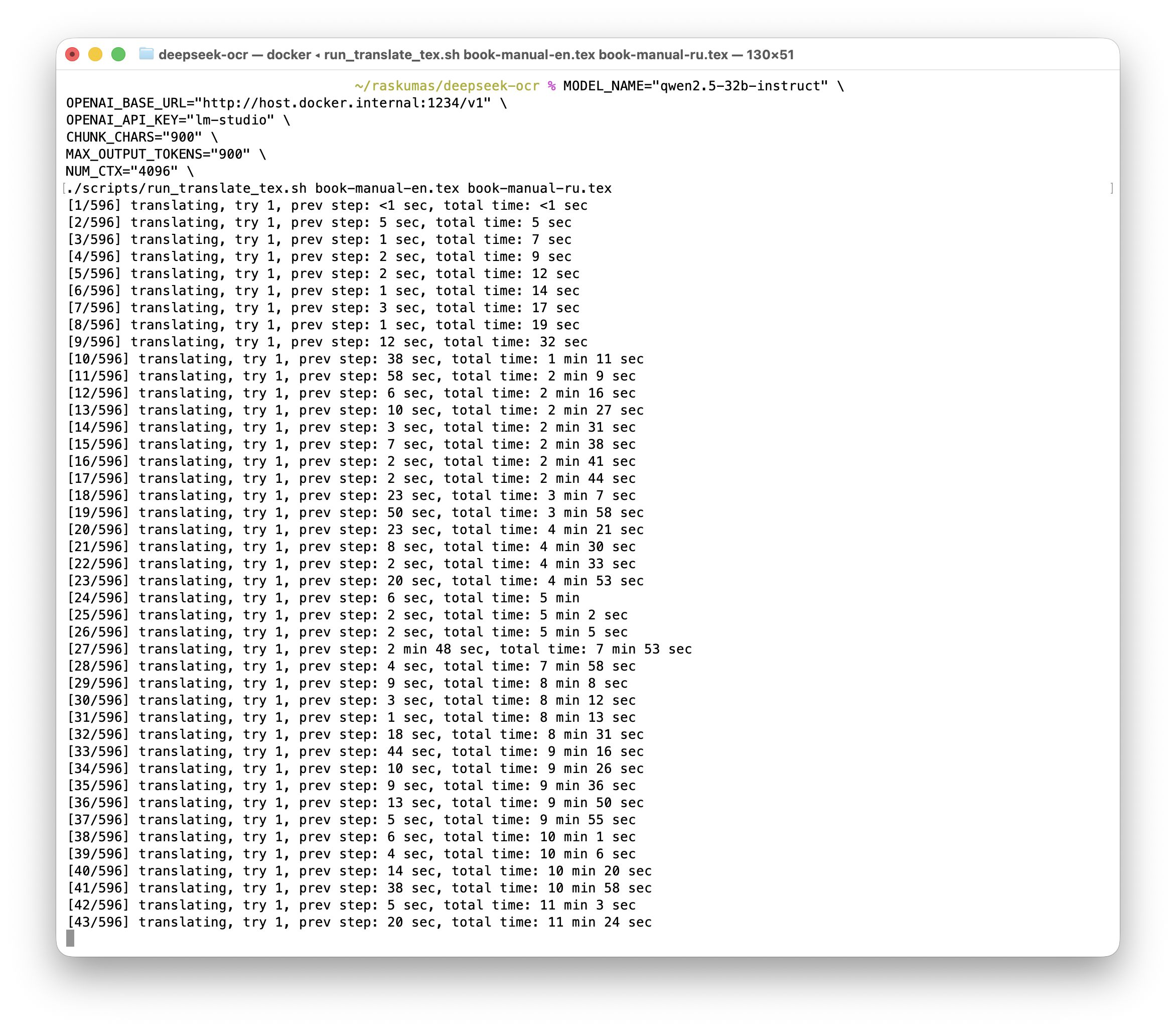
Рисунок 3. Ускоренный профиль на GPU: время перевода одного абзаца около 15 секунд.
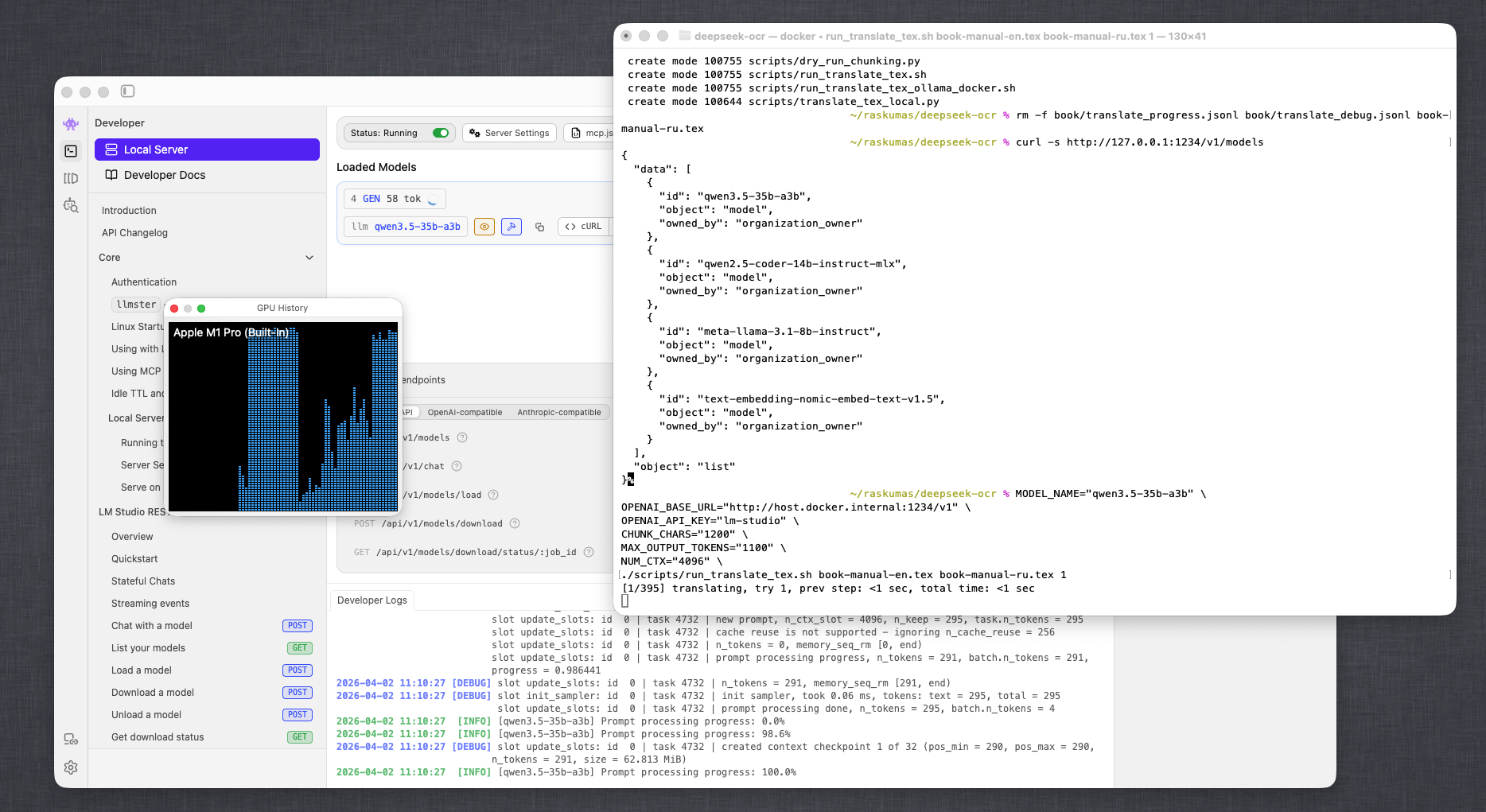
Рисунок 4. Во время прогона видно устойчивую загрузку GPU (LM Studio + системный монитор macOS).
Настройки inference и их влияние
Качество заметно выросло из-за сочетания трёх факторов: меньше степеней свободы у модели (один жёсткий system prompt, без режимов review/retry/heading), более «чистый» вход (в модель идёт только переводимый текст, а не вся LaTeX-разметка), и жёсткая валидация ответа (meta-текст и мусор отбрасываются с повтором).
Кроме выбора модели, сильное влияние дали и параметры inference. Ниже — что изменялось и как это влияло на результат.
temperature: главный рычаг вариативности. Ниже (около0.0) — стабильнее формулировки, меньше англицизмов и «болтовни», что лучше для юридического текста. Выше — больше креативности и больше риск неточных формулировок.top_p: ограничивает «хвост» вероятностей. Приtemperature=0влияет слабо; при более высокомtemperatureменьшийtop_pделает стиль строже, но может обрезать удачные варианты перевода.max_tokens: потолок длины ответа. Слишком низко — обрывы и недосказанность. Слишком высоко само по себе не повышает качество, но снижает риск обрезания длинных кусков.num_ctx: размер контекста, который модель «видит». Больше — лучше связность на длинных чанках, но выше задержка и нагрузка. Значение4096дало рабочий баланс.CHUNK_CHARS(параметр пайплайна): размер переводимого фрагмента. Больше — больше локального контекста, но выше риск деградации и таймаутов. Меньше — стабильнее по времени, но чаще теряется связность между предложениями.
Итог: параметры inference и параметры чанкинга повлияли на результат не меньше, чем выбор модели.
Итоговая техническая схема
- Extract text -> translate -> assemble как базовый поток.
- Выходной
.texпишется сразу с начала прогона, при ошибке чанка пишется fallback, прогон не останавливается. - После полного покрытия включается quality-gate: детекция артефактов и отдельная очередь проблемных чанков.
- Только проблемная часть уходит на доработку (сильнее локальная модель или платный API), затем выполняется финальная сборка.
Важно: была отдельная попытка отправлять в модель LaTeX как есть (целиком с разметкой), но в таком режиме чаще возникали галлюцинации и «поломка» структуры. Поэтому рабочий вариант сделали другим: из LaTeX извлекаются только переводимые текстовые фрагменты, они переводятся отдельно, после чего документ собирается обратно с сохранением исходной разметки.
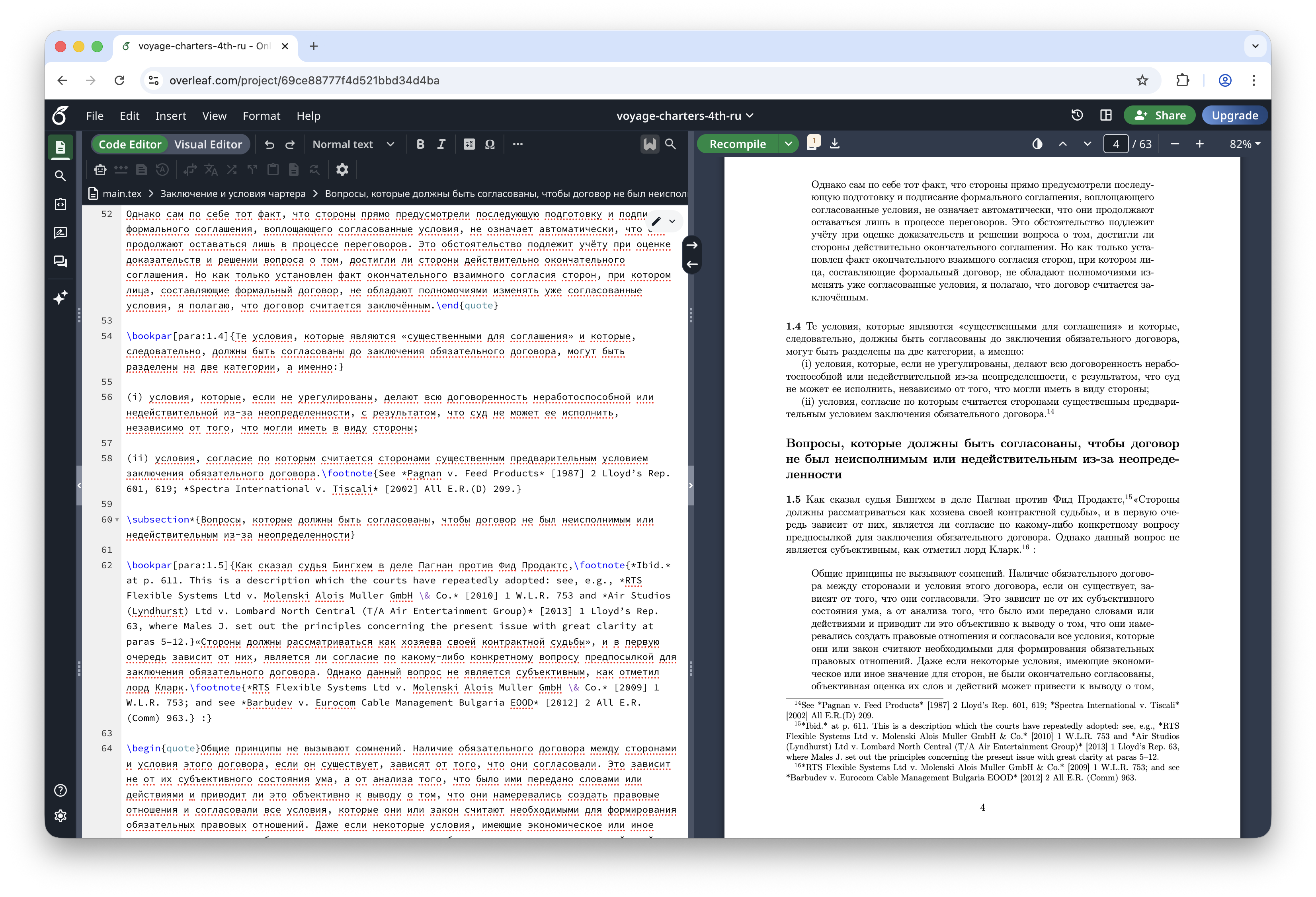
Рисунок 5. Финальный результат: переведённая страница в Overleaf (LaTeX + собранный PDF). Исходный непереведённый блок можно посмотреть в посте про OCR.
Главный технический вывод из PoC: лучший рабочий компромисс для такого класса документов — локальный массовый перевод на 32B-профиле + автоматическая детекция брака + точечная дополировка малого процента сложных фрагментов.